
Introduction
Since we first published CIOL AI Voices in 2023, CIOL Council and delegates at our webinars and Conference days have underlined the importance of enabling linguists to keep up to date with developments in AI with a regularly refreshed resource hub.
Here are some useful recent resources for linguists, which we will continue to add to and update regularly, alongside CIOL AI Voices 2025 and future CIOL Voices pieces
Recent AI Research, News & Articles for Linguists

A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Recent improvements in Large Language Models (LLMs) have led many researchers to focus on building fully autonomous AI agents.
This position paper questions whether such an approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of humans.
The researchers argue that deploying fully autonomous LLM-based agents in complex real-world scenarios, at this stage of development, poses significant risks and limitations that could undermine both safety and effectiveness.
Rather than viewing autonomy as the primary measure of progress, they argue for a fundamental shift toward LLM-based Human-Agent Systems (LLM-HAS), where AI agents function as active teammates rather than independent operators. They advocate for the focused development and deployment of collaborative, supportive, ethical, and adaptive AI-human partnerships that enhance human capabilities while maintaining essential human oversight and judgment.
They say this approach does not represent a retreat from AI’s ambitious goals, but rather a redefinition of what constitutes advanced AI—measuring progress not by isolation, but by collaborative intelligence.

AI translation service launched for fiction writers and publishers prompts dismay among translators
The Guardian reports that GlobeScribe.ai has launched a new AI translation service for fiction writers and publishers, offering translations at $100 per book, per language. Prominent literary translators, however, argue that AI lacks the nuanced understanding required for cultural and contextual depth.
“The best literary translations offer more than simple accuracy, more than literal fidelity to the words making up the sentences,” said Polly Barton, writer and translator of works including the bestselling Butter by Asako Yuzuki from Japanese to English. “They are engaging with the context from which the book has come, and reproducing the pacing, atmosphere, emotional timbre, rhythm, and all the other, less superficially obvious factors that ultimately determine how fulfilling and rich the reading experience is.”
Ian Giles, Chair of the Society of Authors’ Translators Association said: “Suggesting that AI can match, or even surpass, the nuanced work of human translators on behalf of authors is flat-out wrong.”
![]() How Are Interpreters Using AI in 2025?
How Are Interpreters Using AI in 2025?
The latest Slator survey finds that 55% of interpreters surveyed now report using AI tools for their interpreting work, compared to 76% of translators who reported doing so (but only 53 interpreters responded to this question, while 336 translators responded to it.)
When asked how they were using AI in their practice, 19% of the interpreters reported “looking up terminology during interpreting delivery” followed by “extracting named entities and key terms from reference materials,” which was reported by 8% of the surveyed interpreters.

Grammaticality representation in ChatGPT as compared to linguists and laypeople
Large language models (LLMs) have demonstrated exceptional performance across some linguistic tasks. However, it remains uncertain whether LLMs have developed human-like fine-grained grammatical intuition.
This large-scale investigation of ChatGPT’s grammatical intuition, builds upon a previous study that collected laypeople’s grammatical judgments on 148 linguistic phenomena that linguists judged to be grammatical, ungrammatical, or marginally grammatical (Sprouse et al., 2013).
Overall, the findings demonstrate convergence rates ranging from 73% to 95% between ChatGPT and linguists, with an overall average of 89%. These results are attributed to the differences in judgement and in language processing styles between humans and LLMs.
As an example, half of the items exhibiting the greatest human-ChatGPT differences were related to the use of reflexive pronouns. In general, reflexives were judged to be very ungrammatical by ChatGPT, even for the cases that are grammatical to native English speakers. It is likely that when human participants saw sentences with reflexive pronouns, they tended to think of possible discourse contexts that could justify the use of the reflexives. By contrast, ChatGPT’s grammaticality judgment of the reflexive pronouns was based simply on the distribution of the model’s training data.
![]() Google Calls for Rethink of Single-Metric AI Translation Evaluation
Google Calls for Rethink of Single-Metric AI Translation Evaluation
A new study by researchers from Google and Imperial College London challenges a core assumption in AI translation evaluation: that a single metric can capture both semantic accuracy and naturalness of translations. The researchers conclude:
“Single-score summaries do not and cannot give the complete picture of a system’s true performance,”
They observed that systems with the best automatic scores — based on neural metrics — did not receive the highest scores from human raters. “This and related phenomena motivated us to reexamine translation evaluation practices,” they added. The researchers argue that translation quality is fundamentally two-dimensional, encompassing both accuracy (also known as fidelity or adequacy) and naturalness (also known as intelligibility or fluency).
In this paper, they “mathematically prove and empirically demonstrate” that these two goals are in inherent tradeoff — and optimising for one often degrades the other, a point echoed in a recent Slator article that found separating accuracy and fluency improves AI translation evaluation.
![]() How Mature is AI Interpreting?
How Mature is AI Interpreting?
AI speech technologies are rapidly advancing, potentially significantly impacting some parts of the traditionally human-led interpreting market.
Nearly half of respondents in a Slator weekly poll believe AI interpreting can be effective for niche scenarios, although almost a third believe that it is still highly experimental. However, the sample size was small (31 respondents) and the highly variable performance of AI by language was not part of the framing of the question.
![]() To understand the future of AI, take a look at the failings of Google Translate
To understand the future of AI, take a look at the failings of Google Translate
This article discusses the limitations of Google Translate, and how they highlight the broader challenges faced by AI.
Despite significant advancements, machine translation still struggles with idioms, place names, and technical terms, indicating that AI has a long way to go before achieving true linguistic and contextual understanding. The final paragraphs conclude: "...the forseeable future for LLMs is one in which they are excellent at a few tasks, mediocre in others, and unreliable elsewhere. We will use them where the risks are low, while they may harm unsuspecting users in high-risk settings."
The author asks: "The urgent question: is this really the future we want to build?"
![]() Meta’s BOUQuET Brings Linguistic Diversity to AI Translation Evaluation
Meta’s BOUQuET Brings Linguistic Diversity to AI Translation Evaluation
Meta unveiled BOUQuET, a comprehensive dataset and benchmarking initiative aimed at improving multilingual machine translation (MT) evaluation. The researchers noted that existing datasets and benchmarks often fall short due to their focus on English, narrow range of registers, reliance on automated data extraction and limited language coverage. These constraints hinder the ability to fairly evaluate translation quality across diverse linguistic contexts.
BOUQuET addresses these gaps by originating content in seven non-English languages — French, German, Hindi, Indonesian, Mandarin Chinese, Russian, and Spanish — before translating into English.
![]()
Experts Weigh In on DeepSeek AI Translation Quality
Chinese AI company DeepSeek launched two open-source large language models in January 2025 - DeepSeek-R1 and DeepSeek-V3 - generating significant attention for their ChatGPT-level performance at lower costs. Based in Hangzhou, the company achieved this through efficient training methods including improved Mixture of Experts (MoE) technique, allowing the models to be trained on lower-end hardware while maintaining high performance.
User feedback indicates strong translation capabilities across multiple languages, with particular excellence in Chinese-English translation. Users reported superior performance compared to other models in languages including Serbian, Spanish, Turkish, Czech, Hungarian, Punjabi, and Malayalam. Business adoption has proven cost-effective, with one CEO reporting 50x cost reduction compared to Google Translate, though some users still prefer alternatives like Claude or Copilot.
![]() SAFE AI founding members join SlatorPod to discuss AI and Interpreting
SAFE AI founding members join SlatorPod to discuss AI and Interpreting
Katharine Allen, Director of Language Industry Learning at Boostlingo, and Dr. Bill Rivers, Principal at WP Rivers & Associates, join SlatorPod to discuss the challenges and opportunities AI brings to interpreting. Both are founding members of the Interpreting SAFE AI Task Force, which aims to guide the responsible use of AI in language services (for more on SAFE AI see below).
Allen describes AI as a double-edged sword — capable of expanding multilingual access but limited in its ability to handle the nuanced human dialogue essential in fields like healthcare. She emphasizes the ongoing shift toward a hybrid model, where human interpreters collaborate with AI tools.
![]() Google Finds ‘Refusal to Translate’ Most Common Form of LLM Verbosity
Google Finds ‘Refusal to Translate’ Most Common Form of LLM Verbosity
Researchers from Google have identified 'verbosity' as a key challenge in evaluating large language models (LLMs) for machine translation (MT). Verbosity refers to instances where LLMs provide the reasoning behind their translation choices, offer multiple translations, or refuse to translate certain content. This behavior contrasts with traditional MT systems, which are optimized for producing a single translation.
The study found that verbosity varies across models, with Google's Gemini-1.5-Pro being the most verbose and OpenAI’s GPT-4 among the least verbose. The most common form of verbosity was refusal to translate, notably seen in Claude-3.5.
A major concern is that current translation evaluation frameworks do not account for verbose behaviors, often penalizing models that exhibit verbosity, which can distort performance rankings. The researchers suggest two possible solutions: modifying LLM outputs to fit standardised evaluation metrics or updating evaluation frameworks to better accommodate varied responses. However, these solutions may not fully address verbosity-induced errors or reward 'useful' verbosity, highlighting the need for more nuanced evaluation methods.
 AI Pioneer Thinks AI Is Dumber Than a Cat
AI Pioneer Thinks AI Is Dumber Than a Cat
Yann LeCun helped give birth to today’s artificial-intelligence boom. But he thinks many experts are exaggerating its power and peril, and he wants people to know it.
“We are used to the idea that people or entities that can express themselves, or manipulate language, are smart—but that’s not true,” says LeCun.
“You can manipulate language and not be smart, and that’s basically what LLMs are demonstrating.”
Today’s models are really just predicting the next word in a text, he says. But they’re so good at this that they fool us. And because of their enormous memory capacity, they can seem to be reasoning, when in fact they’re merely regurgitating information they’ve already been trained on.
![]() Google Aligns LLM Translation with Human Translation Processes
Google Aligns LLM Translation with Human Translation Processes
Google researchers have developed a new multi-step process to improve translation quality in large language models (LLMs) by mimicking human translation workflows. This approach involves four stages: pre-translation research, drafting, refining, and proofreading and aims to enhance accuracy and context in translations. Tested across ten languages, this method outperformed traditional translation techniques, especially in translations where context is crucial.
![]() How the Media Covers the 'AI vs Translators' Debate
How the Media Covers the 'AI vs Translators' Debate
Slator reports that translation is one of the most-referenced professions in 2024's media coverage of AI’s potential impact. Generally, according to Slator, media opinions on AI and translation can be grouped into one of four categories: "Humans Are Still Superior (For Now)" with c25% of articles, "Translators Are In Danger", accounting for c40% of articles, "AI + Humans = Optimal Translation" was the message of around 20% of articles and finally c15% of articles talked about translation but without mentioning translators at all. A mixed picture at best.
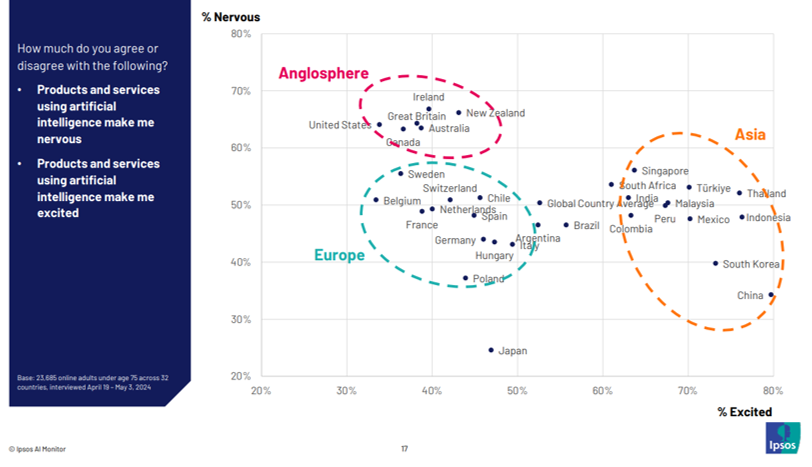
Ipsos - The Ipsos AI Monitor
Among a wealth of other data, the Ipsos AI Monitor 2024 suggested attitudes to AI differ significantly around the world.
Respondents from English-speaking countries are far more 'nervous' about AI than in Asian countries, led by China and South Korea, where respondents are far more 'excited' . In EU countries, respondents are both less 'excited' and less 'nervous', perhaps reflecting the increasingly more structured regulatory environment for AI in the EU.
Given these attitude differences, the use and impact of AI in translation, interpreting and language learning may unfold very differently in different countries and regions around the world in the years to come.
Nature - Larger and more instructable language models become less reliable
This article from Nature discusses the reliability of large language models (LLMs), and notes that while large language models (LLMs) have improved in accuracy, they have also become less reliable. Larger models tend to provide answers to almost every question, increasing the likelihood of incorrect responses. The study shows that these models often give seemingly sensible but wrong answers, especially on difficult questions that human supervisors might overlook.
The findings suggest a need for a fundamental shift in the design and development of general-purpose AI, particularly in high-stakes areas. As LLMs are increasingly used in fields like education, medicine, and administration, users must carefully supervise their operation and manage expectations. The research analysed several LLM families, noting that while these models have become more powerful, their tendency to avoid admitting to ignorance and to provide incorrect answers poses significant challenges in their adoption and use.
Radboud University - Don’t believe the hype: AGI is far from inevitable

Creating artificial general intelligence (AGI) with human-level cognition is ‘impossible’, according to Iris van Rooij, lead author of the paper and professor of Computational Cognitive Science, who heads the Cognitive Science and AI department at Radboud University. ‘Some argue that AGI is possible in principle, that it’s only a matter of time before we have computers that can think like humans think. But principle isn’t enough to make it actually doable. Our paper explains why chasing this goal is a fool’s errand, and a waste of humanity’s resources.’
In their paper, the researchers introduce a thought experiment where an AGI is allowed to be developed under ideal circumstances. Olivia Guest, co-author and assistant professor in Computational Cognitive Science at Radboud University: ‘For the sake of the thought experiment, we assume that engineers would have access to everything they might conceivably need, from perfect datasets to the most efficient machine learning methods possible. But even if we give the AGI-engineer every advantage, every benefit of the doubt, there is no conceivable method of achieving what big tech companies promise.’
That’s because cognition, or the ability to observe, learn and gain new insight, is incredibly hard to replicate through AI on the scale that it occurs in the human brain. ‘If you have a conversation with someone, you might recall something you said fifteen minutes before. Or a year before. Or that someone else explained to you half your life ago. Any such knowledge might be crucial to advancing the conversation you’re having. People do that seamlessly’, explains van Rooij.
‘There will never be enough computing power to create AGI using machine learning that can do the same, because we’d run out of natural resources long before we'd even get close,’ Olivia Guest adds.
Microsoft Future of Work Report 2024

Microsoft's 2024 Future of Work Report revealed a critical inflection point in AI's impact on language work.The report suggests that for language professionals, the shift is twofold: from pure translation/interpretation to higher-order skills like cultural adaptation and quality assurance; and from viewing AI as a replacement to seeing it as a collaborative tool requiring expertise in prompt engineering and output verification. The report documents real productivity gains in document creation and email processing, while emphasising that human expertise remains essential for cultural nuance and context.
However, the report flags serious concerns about AI's current limitations with low-resource languages, potentially excluding billions from the digital economy. When AI systems do handle these languages, they typically deliver lower quality outputs at higher costs with less cultural relevance. While initiatives like Masakhane and ELLORA are working to address these gaps through community-driven datasets and technological innovation, the report emphasises that success requires both technological advancement and deep engagement with local linguistic and cultural knowledge, moving away from the 'extractive' data practices of the past.
In 2023 Microsoft flagged (on p36) the important concept of an increased risk of “moral crumple zones". It pointed out that studies of past 'automations' teach us that when new technologies are poorly integrated within work/organisational arrangements, workers can unfairly take the blame when a crisis or disaster unfolds. This can occur when automated systems only hand over to humans at the worst possible moments, when it is very difficult to either spot, fix or correct the problem before it is too late. A very real concern for linguists.
This could be compounded by 'monitoring and takeover challenges' (set out on p35) where jobs increasingly require individuals to oversee what intelligent systems are doing and intervene when needed. However studies reveal potential challenges. Monitoring requires vigilance, but people struggle to maintain attention on monitoring tasks for more than half an hour, even if they are highly motivated. Again a problem for linguists in post editing or AI assisted interpreting contexts.
These will likely be challenges linguists will face, alongside the many possibilities and opportunities that these reports calls out.
AIIC - M.A.S.T.E.R. the Message, not the Code

Since 1953, AIIC has been promoting the highest standards of quality and ethics in interpreting. With M.A.S.T.E.R the message, AIIC is launching a new campaign to highlight the irreplaceable value of human expertise. With the increasing use of AI and automation, AIIC thinks it is essential to shine a light on the critical role human interpreters play.
Professional interpreters facilitate cross-cultural communication, ensuring accuracy, security, and ethical practice. But AIIC recognises the need for up-to-date technology to help speed up processes so interpreters can do what they do best. While technology has its place, AIIC believes human interpreters offer a unique blend of empathy, cultural understanding, and real-time adaptability that AI will never be able to replicate.
Throughout their campaign, AIIC will be advocating for a collaborative approach, where human expertise and technology work together to achieve the best possible outcomes.
SAFE AI Task Force Guidance and Ethical Principles on AI and Interpreting Services

This Interpreting SAFE guidance from the SAFE AI Task Force in the USA establishes four fundamental principles as a durable, resilient and sustainable framework for the language industry. The four principles are drawn from ethical, professional practices of high and low resource languages, and are intended to drive legal protections and promote innovations in fairness and equity in design and delivery so that all can benefit from the potential of AI interpreting products.
A broad cross-section of stakeholders participated in designing the Interpreting SAFE AI framework, which is intended guidance for policymakers, tech companies/vendors, language service agencies/providers, interpreters, interpreting educators, and end-users.
More AI News & Articles for Linguists
 110 new languages are coming to Google Translate
110 new languages are coming to Google Translate
Google announced it is using AI to add 110 new languages to Google Translate, including Cantonese, NKo and Tamazight. Google announced the 1,000 Languages Initiative in 2022, a commitment to build AI models that will support the 1,000 most spoken languages around the world. Using its PaLM 2 large language model, Google is adding these languages as part of its largest expansion of Google Translate to date.
![]()
AI Translation ‘Extremely Unsuitable’ for Manga, Japan Association of Translators Says
Slator reports that the Japan Association of Translators (JAT) issued a bilingual statement in June 2024 to express “strong reservations” over the use of high-volume AI translation of manga, noting that AI has not demonstrated a consistently high-quality approach to nuance, cultural background, and character traits — all of which play a major part in manga.
“Based on our experience and subject-matter expertise, it is the opinion of this organization that AI translation is extremely unsuitable for translating high-context, story-centric writing, such as novels, scripts, and manga,” JAT wrote. “Our organization is deeply concerned that the public and private sector initiative to use AI for high-volume translation and export of manga will damage Japan’s soft power.”
Brave new booth - UN Today

This article, Interpreting at the dawn of the age of AI, in UN Today (the official staff magazine of the UN) discusses the limitations of AI in language services, particularly interpreting. It argues that AI, in its current form, cannot replace human interpreters due to the inherent complexities of human communication, which involve not just speech but also non-verbal cues and cultural context.
Experts highlight that AI systems 'mimic' rather than truly interpret language, and they lack the emotional intelligence and ethical decision-making required for sensitive interpreting situations. The article also raises concerns about AI's potential biases and inaccuracies, urging a cautious approach to adopting AI interpreting solutions and emphasising the irreplaceable value of human interpreters' skills and empathy.
Generative AI and Audiovisual translation
Noting the increasing use of generative AI in many industries and for a variety of highly creative tasks, AVTE (Audiovisual Translators of Europe) has issued a Statement on AI regulation.
AVTE note that Audiovisual translation is a form of creative writing and that it is not against new technologies per se, acknowledging they can benefit translators, as long as they are used for improving human output and making work more ergonomic and efficient. What they are against is the theft of human work, the spread of misinformation as well as unethical misuse of generative AI by translation companies and content producers.
No-one left behind, no language left behind, no book left behind
![]()
CEATL, the European Council of Literary Translators' Associations has published its stance on generative AI. CEATL notes that since the beginning of 2023, the spectacular evolution of artificial intelligence, and in particular the explosion in the use of generative AI in all areas of creation, has raised fundamental questions and sparked intense debate.
While professional organisations are coordinating to exert as much influence as possible on negotiations regarding the legal framework for these technologies (see in particular the statement co-signed by thirteen federations of authors’ and performers’ organisations), CEATL has drafted its own statement detailing its stance on the use of generative AIs in the field of literary translation.
Older AI News & Articles for Linguists

AI Chatbots Will Never Stop Hallucinating
This article discusses the phenomenon of “hallucination” in AI-generated content, where large language models (LLMs) produce outputs that don’t align with reality. It highlights that LLMs are designed first and foremost to generate responses and not factual accuracy, leading to inevitable errors. The article suggests that to minimize hallucinations, AI tools need to be paired with fact-checking systems and supervised. It also explores the limitations and risks of LLMs due to marketing hype, the constraints of data storage and processing and the inevitable trade-offs between speed, responsiveness, calibration and accuracy.

This article discusses how the quality of data used to train large language models (LLMs) affects their performance in different languages, especially those with less original high-quality content on the web. It reports on a recent paper by researchers from Amazon and UC Santa Barbara, who found that a lot of the data for less well-resourced languages was machine-translated by older AIs, resulting in lower-quality output and more errors. The article also explores the implications of this finding for the future of generative AI and the challenges of ensuring data quality and diversity.

Generative AI - The future of translation expertise
This article explores the transformative potential of generative AI in the translation industry. It illustrates how translators may be able to enhance their work quality and efficiency using generative AI tools (notably the OpenAI Translator plugin with Trados Studio) and the importance of 'prompt' design in achieving desired outputs. The article emphasises, however, that generative AI will augment rather than replace human translators by automating routine tasks, and encourages translators to adapt to and adopt AI as these tools herald new opportunities in the field.
![]() Are Large Language Models Good at Translation Post-Editing?
Are Large Language Models Good at Translation Post-Editing?
The article discusses a study on the use of large language models (LLMs), specifically GPT-4 and GPT-3.5-turbo, for post-editing machine translations. The study assessed the quality of post-edited translations across various language pairs and found that GPT-4 effectively improves translation quality and can apply knowledge-based or culture-specific customizations. However, it also noted that GPT-4 can produce hallucinated edits, necessitating caution and verification. The study suggests that LLM-based post-editing could enhance machine-generated translations' reliability and interpretability, but also poses challenges in fidelity and accuracy.
![]() Who will write the rules for AI? How nations are racing to regulate artificial intelligence?
Who will write the rules for AI? How nations are racing to regulate artificial intelligence?
This article from The Conversation analyses the three main models of AI regulation that are emerging in the world: Europe’s comprehensive and human-centric approach, China’s tightly targeted and pragmatic approach, and America’s dramatic and innovation-driven approach. It also examines the potential benefits and drawbacks of each model, and the implications for global cooperation and competition on AI.
![]() Amazon Flags Problem of Using Web-Scraped Machine-Translated Data in LLM Training
Amazon Flags Problem of Using Web-Scraped Machine-Translated Data in LLM Training
Amazon researchers have discovered that a significant portion of web content is machine translated, often poorly and with bias. In their study, they created a large corpus of sentences in 90 languages to analyze their characteristics. They found that multi-way translations are generally of lower quality and differ from 2-way translations, suggesting a higher prevalence of machine translation. The researchers warn about the potential pitfalls of using low-quality, machine-translated web-scraped content for training Large Language Models (LLMs).
 Generative AI: Friend Or Foe For The Translation Industry?
Generative AI: Friend Or Foe For The Translation Industry?
This article discusses the potential impact of generative AI (GenAI) on the translation industry, noting the high degree of automation and of machine learning algorithms which already exists, and argues that GenAI will not cause a radical disruption, but rather an acceleration of the current trend of embedding automation and re-imagining translation workflows. The author also suggests that content creators will need translation professionals more than ever to handle the increase in content volumes and to navigate assessment, review and quality control of GenAI-generated content.
Intento - Generative AI for Translation in 2024

This new study from Intento explores the dynamic landscape of Generative AI (GenAI), and the comparative performance of new models with enhanced translation capabilities. Following updates from leading providers such as Anthropic, Google, and OpenAI, this study selected nine large language models (LLMs) and eight specialized Machine Translation models to assess their performance in English-to-Spanish and English-to-German translations.
The methodology employed involved using a portion of a Machine Translation dataset, focusing on general domain translations as well as domain-specific translations in Legal and Healthcare for English-to-German. To optimise the use of LLMs for translation, the researchers crafted prompts that minimized extraneous explanations, a common trait in conversationally designed LLMs. Despite these efforts, models still produced translations with unnecessary clarifications, which had to be addressed through post-processing.
The findings revealed that while LLMs are slower than specialized models, they offer competitive pricing and show promise in translation quality. The study used 'semantic similarity' scores to evaluate translations, with several models achieving top-tier performance. However, challenges such as hallucinations, terminology issues, and overly literal translations were identified across different LLMs. The research concluded that while specialized MT models lead in-domain translations, LLMs are making significant strides and could become more domain-specific in the future. For professional translators, these insights underscore the evolving capabilities and potential of GenAI in the translation industry.
Stanford University - 2024 AI Index Report

The 2024 Index is Stanford's most comprehensive to date and arrives at an important moment when AI’s influence on society has never been more pronounced. This year, they have broadened their scope to more extensively cover essential trends such as technical advancements in AI, public perceptions of the technology, and the geopolitical dynamics surrounding its development.
Key themes are:
- AI beats humans on some tasks, but not on all.
- Industry continues to dominate frontier AI research.
- Frontier models (i.e. cutting edge) get way more expensive.
- The US leads China, the EU, and the UK as the leading source of top AI models.
- Robust and standardized evaluations for Large Language Models (LLMs) responsibility are seriously lacking.
- Generative AI investment has 'skyrocketed'.
- AI makes workers more productive and leads to higher quality work.
- Scientific progress is accelerating even further, thanks to AI.
- The number of AI regulations in the United States is sharply increasing.
- People across the globe are more cognizant of AI’s potential impact—and more nervous.
This edition introduces new estimates on AI training costs, detailed analyses of the responsible AI landscape, and a new chapter dedicated to AI’s impact on science and medicine. The AI Index report tracks, collates, distills, and visualizes a wide range of the latest data related to artificial intelligence (AI).
Elon University - Forecast impact of artificial intelligence by 2040

This report from Elon University, a US liberal arts, sciences and postgraduate university, predicts significant future upheavals due to AI, requiring reimagining of human identity and potential societal restructuring.
Combining public and expert views, both groups expressed concerns over AI's effects on privacy, inequality, employment, and civility, while also acknowledging potential benefits in efficiency and safety.
Analysis of several commissioned expert essays revealed five emerging themes: 1) Redefining humanity, 2) Restructuring societies, 3) Potential weakening of human agency, 4) Human misuse of AI and 5) Anticipated benefits across various sectors.

Mixed opinions on AI's overall future impact highlight very real concerns about privacy and employment, alongside a more positive outlook for healthcare advancements and leisure time.
UK Government's Generative AI Framework: A guide for using generative AI in government

This document provides a practical framework for civil servants who want to use generative AI. It covers the potential benefits, limitations and risks of generative AI, as well as the technical, ethical and legal considerations involved in building and deploying generative AI solutions in a government context.
The framework is divided into three main sections: Understanding generative AI, which explains what generative AI is, how it works and what it can and cannot do; Building generative AI solutions, which outlines the practical steps and best practices for developing and implementing generative AI projects; and Using generative AI safely and responsibly, which covers the key issues of security, data protection, privacy, ethics, regulation and governance that need to be addressed when using generative AI.
It sets out ten principles that should guide the safe, responsible and effective use of generative AI in government and public sector organisations.
These are:
- You should know what generative AI is and what its limitations are
- You should use generative AI lawfully, ethically and responsibly
- You should know how to keep generative AI tools secure
- You should have meaningful human control at the right stage
- You should understand how to manage the full generative AI lifecycle
- You should use the right tool for the job
- You should be open and collaborative
- You should work with commercial colleagues from the start
- You should have the skills and expertise needed to build and use generative AI
- You should use these principles alongside your organisation’s policies and have the right assurance in place
The framework also provides links to relevant resources, tools and support as well as a set of posters with the key messages boldly set out, as below:


A transparent framework is clearly to be welcomed. From the perspecitive of linguists working with UK government, these principles also give a useful framework for accountabilty and the means to ask reasonable questions about policies and practice that may affect their work.
Read the 'CIOL AI Voices' White Paper

Click the image or download the PDF here.
